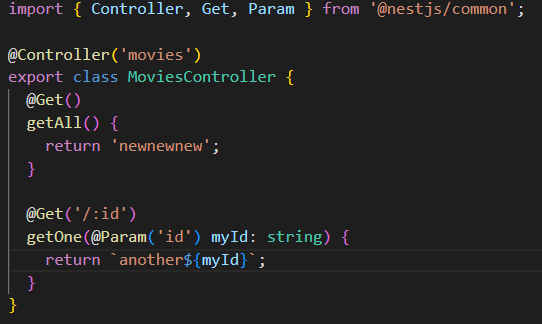
public class AAAA
{
public int x, y;
public AAAA()
{
실행문 내용 생략
}
}
위 코드에서, public이 접근 한정자에 해당하고
접근 한정자는 public, protected, internal, protected internal, private, private protected가 있다.
public은 밖에서 액세스가 가능한 것을 의미한다.
protected는 이 클래스와 이 클래스에서 파생된 클래스로만 액세스 할 수 있다.
internal은 현재 어셈블리로만 액세스가 제한된다.
protected internal는 포함하는 클래스와 포함하는 클래스에서 파생된 클래스와 어셈블리내의 클래스만 액세스가 된다.
private는 이 클래스에서만 접근이 가능하다
private protected는 포함하는 클래스와 동일 어셈블리 내의 포함하는 유형으로부터 파생된 클래스만 액세스가 된다.
...뭔가 엄청 복잡하고 많은데 사실 대부분은 잘 안쓰는 거고
public과 private를 가장 많이 사용하며 protected도 종종 사용된다.
아래 예시를 보자
class AA{
int a;
public int b, c;
public void Print(){
Console.WriteLine(a,b,c);
}
}
class Program
{
static void Main(string[] args){
AA aa = new AA();
//aa.a = 5; 는 사용불가
aa.b = 10;
aa.c = 20;
aa.Print();
}
}
AA 클래스에는 int가 각각 a, b, c가 선언되어 있다.
이때, a만 접근한정자가 없는데, 이 경우 private가 기본적으로 적용된다.
b와 c는 public으로 정의되어 있으며
Print함수 또한 public으로 정의되어 있다.
아래 Program 클래스를 보자
Main함수에서, 후술할 생성자를 통해 AA 클래스를 쓰겠다고 했으며 이를 aa라고 명명했다.
AA 클래스에는 변수 a, b, c와 Print 함수가 있는데
b와 c의 값은 여기서 정해주는 것이 가능하나 a는 정해줄 수 없다.
왜냐하면 private 인 값은 다른 클래스에서 조작할 수 없기 때문이다.
반면 public인 b와 c와 Print는 얼마든지 사용가능한 것을 볼 수 있다.
생성자와 소멸자
바로 위에서, Main함수에서 AA 클래스를 사용하기 위해 new 키워드를 쓴 것을 볼 수 있다.
이것이 바로 생성자로 객체를 생성할 때 사용한다.
즉, AA클래스를 새로 하나 복사를 해서 이 클래스에서 쓰겠다는 것이며 이 사본의 이름을 aa라고 지은 것이다.
그렇다면 소멸자는 뭘까
소멸자는 GC라고도 하며 ~키워드를 사용한다.
여기서 ~는 클래스 앞에 붙여서 사용한다.
만약 위의 AA클래스에 소멸자를 붙인다면 ~AA가 되는 것이다.
아래 예시를 보자
class AA{
int a;
float b;
public AA(){
a = 0;
b = 0f;
}
public AA(int aa, float bb){
a = aa;
b = bb;
}
~AA(){
Console.WriteLine("제거")
}
}
class Program
{
static void Main(string[] args){
AA aa = new AA();
AA aaaa = new AA(100, 0.5f);
}
}
시작하기 전에, AA클래스 안에는 AA가 총 두 종류가 있는 것을 볼 수 있다.
하나는 파라미터를 2개 받는 것이고 나머지 하나는 파라미터를 안 받는 것이다.
Main 함수에서, 파라미터를 받는 함수와 받지 않는 함수를 각각 따로 호출하고 있다.
여기서 소멸자는 AA 클래스 내의 모든 호출이 끝나면 자동으로 소멸자가 호출한 횟수만큼 작동한다.
위 코드에서는 AA 클래스를 총 2번 호출했으므로 "제거"라는 문자열이 두 번 등장할 것이다.
주의사항
생성자와 소멸자의 이름은 클래스의 이름과 같다.
생성자와 소멸자는 리턴이 없다.
생성자는 접근한정자를 쓰고 클래스의 이름을 넣어주면 된다.(자료형을 넣지 않는다.)
소멸자에는 어떠한 파라미터도 넣어줄 수 없다.
클래스 안에 생성자가 하나라도 선언되어 있을 경우 기본으로 제공하는 선언자가 작동하지 않는다.
이게 무슨말이냐면 아래 코드를 보자
class AA{
public AA(){
}
public AA(int aa, float bb){
}
}
class Program
{
static void Main(string[] args){
AA aa = new AA();
AA aaaa = new AA(100, 0.5f);
}
}
static int AAA(int a, int b)
{
int c = a * b / 2
return c
}
여기서 int a와 int b가 내가 입력해야할 가로길이와 세로길이가 된다.
c는 넓이가 된다.
AAA는 내가 만든 함수의 이름이 된다.
그렇다면 이 함수를 써보자
static int AAA(int a, int b)
{
int c = a * b / 2
return c
}
int num1 = 10;
int num2 = 30;
int result = AAA(num1, num2)
Console.WriteLine(result)
이렇게 하면 함수 AAA에 각각 10과 30이라는 숫자가 들어가고
그 결과값이 result에 저장될 것이다.
모든 함수가 파라미터와 리턴이 존재하는 것은 아니다.
파라미터가 없는 함수도 있고 리턴이 없는 함수도 있고 둘 다 없는 함수도 있다.
리턴이 없는 함수는 void를 써주어야 한다.
Call by Value와 Call by Reference
Call by Value는 값에 의한 호출로 함수에서 값에 영향을 주지 않는다.
Call by Reference는 주소에 의한 호출로 함수에서 값에 영향을 준다.
주소에 의한 호출을 사용하고 싶다면 파라미터의 자료형 앞에 ref를 붙여주면 된다.
아래 예제를 참조하자
static public void ValueSwap(int a, int b)
{
int temp = a;
a = b;
b = temp;
}
static public void RefSwap(ref int a, ref int b)
{
int temp = a;
a = b;
b = temp;
}
static void Main(string[] args)
{
int num1 = 100;
int num2 = -100;
ValueSwap(num1, num2);
Console.WriteLine(num1, num2);
RefSwap(ref num1, ref num2);
Console.WriteLine(num1, num2);
}
메인함수를 포함하여, 총 3개의 함수가 있다.
맨 처음 ValueSwap는 값에 의한 호출로 파라미터 값을 서로 스위핑 해주고
RefSwap는 참조에 의한 호출로 파라미터 값을 서로 스위핑 해준다.
Main 함수를 보면 num1 은 100, num2는 -100로 되어있다
ValueSwap 함수 내에서, num1과 num2의 값은 서로 바뀌겠지만
그것은 어디까지나 함수 내에서만 발생하는 것이며, 함수 밖의 값은 전혀 영향이 가지 않는다.
그러나 RefSwap 함수 내에서, num1 값과 num2 값은 서로 바뀌고 그것이 함수 밖의 원본에까지
영향을 끼친다.
out
out은 ref와 사용방법이 같은 키워드로 전달하는 변수 초기화 없이 사용 가능하다
보통 out을 쓰는 경우, 리턴이 없는 경우가 꽤 있다.
static void InitNum(out int addNum)
{
addNum = 100;
}
static void InitRefNum(ref int addNum)
{
refNum = 100;
}
static void Main(string[] args)
{
int a;
int b;
InitNum(out a);
Console.WriteLine(a) // 출력 결과는 100
InitRefNum(ref b); // 에러!! b를 초기화 하지 않고 사용할 수 없음!!
Console.WriteLine(b)
}
메인함수의 InitNum을 보자, 초기화가 안 된 변수 a가 out 키워드와 함께 파라미터로 들어갔다.
그리고 그렇게 들어간 파라미터는 주소에 의한 호출값이므로
원본 값 a의 값을 변화시킨다.
반면 InitRefNum 같은 경우, 위 코드대로 하면 에러가 발생한다.
b값이 초기화 되지 않았기 때문에 사용할 수 없기 때문이다.
즉 ref과 out의 차이는 초기화가 필요한가 아닌가로 나눌 수 있을 것이다.
파라미터 초기화
파라미터는 뒤에서 순서대로 초기화 된다.
static void AAAA(int a, int b, int c = 100, int d = 0)
{
Console.WriteLine(a, b, c, d);
}
static void Main(string[] args)
{
AAAA(0, 0, 0, 0);
}
AAAA라는 함수를 정의했고, Main함수에서, AAAA함수에 0, 0, 0, 0을 넣었다.
이 경우, AAAA 함수 내에서, a, b, c, d의 값은 전부 0을 받고 Console.WriteLine을 통해, 0 0 0 0이 출력된다.
그렇다면 파라미터에서 int c = 100은 무슨 역할을 하느냐
만약 AAAA(10, 2) 를 Main 함수에 넣을 경우, int c와 int d는 파라미터를 받지 못하게 된다.
이럴 경우, 기본 값으로써 c는 100, d는 0을 받게 되는 것이다.
파라미터는 반드시 뒤에서 순서대로 초기화 된다.
때문에 아래 구문처럼 작성할 수 없다.
static void AAAA(int a, int b = 50, int c, int d = 0)
{
Console.WriteLine(a, b, c, d);
}
c는 기본 값이 주어지지 않았는데, b에 기본값을 넣어줄 수 없다.
즉 기본값은 반드시 뒤에서부터 순서대로 와야 한다.
메소드 오버로딩
메소드 오버로딩이란 메소드 이름이 중복되는 것을 말한다.
C#에서는 함수의 이름을 동일하게 사용할 수 있다.
물론 이 경우, 엄청난 에러가 발생할 수 있지만, 나름대로 구분법이 있으니
이름은 같아도, 파라미터의 수나 타입이 다르면 별개의 함수로 인식한다.
아래 예시를 보자
static int AAAA(int a, int b)
static int AAAA(int a, int b, int c)
static int AAAA(float a, float b)
AAAA라는 이름의 함수가 3개나 선언되었지만 파라미터가 전부 따로 노는 만큼 각자 다른 함수로 인식한다.
이것이 바로 오버로딩이다.
그러나 이는 다음과 같은 상황에서 심각한 부작용을 초래할 수 있다.
static void AAAA(int a, int b, int c)
{
return (a + b + c + d)
}
static void AAAA(int a, int b, int c, int d = 23)
{
return (a + b + c + d) * 2
}
static void Main(string[] args)
{
Console.WriteLine(AAAA(11,22,33))
}
자, AAAA 함수가 두 개가 선언되어 있다.
두번째 AAAA함수의 파라미터 d는 디폴트 값 23 을 가진다.
Main함수에서, AAAA함수에 파라미터를 3개를 넣었다.
이때, 과연 어떤 함수가 실행될지 예상할 수 있는가?
당연히 모호성으로 인한 오류가 발생하게 된다.
때문에 위 코드는 아래와 같이 수정해줄 필요가 있다.
static void AAAA(int a, int b, int c)
{
return (a + b + c + d)
}
static void AAAA(int a, int b, int c, int d) //기본값을 제거
{
return (a + b + c + d) * 2
}
static void Main(string[] args)
{
Console.WriteLine(AAAA(11,22,33))
}
int a;
{
int b;
int a; // 이건 애러!!
}
{
int b;
}
b = 10; // 이것도 애러
위 식을 보자
맨 처음 int a가 선언되었다.
그리고 괄호 안의 int a는 사용이 불가능 한데 이미 사용중인 이름이기 때문이다.
반면 아래 따로 격리된 괄호 안에서는 b를 사용할 수 있다.
그리고 괄호 밖에 벗어나있는 b는 애러라고 뜬다.
위의 두 int b는 어디까지나 그 괄호 안에서만 유효하기 때문에
가장 밖의 공간에서는 int b가 선언된 적이 없으므로 사용이 불가능 한 것이다.
다른 괄호 안에 있기 때문인데 이를 지역변수라고 한다.
분기문(branch)
if 문(조건문)
if문은 가장 중요하면서도 자주 사용하는 분기문이다.
C# 뿐만 아니라 다른 언어에서도 흔하며 어디서나 자주 쓰기 때문에 이건 꼭 알고 넘어갈 필요가 있다.
if (조건식) {
실행문
}
형태는 위와 같다.
조건식이 true이면 실행문을 실행하고 false면 실행하지 않는다.
if (조건식){
실행문
}else {
실행문
}
비슷한 형태의 if ~ else 문이다.
만약 조건식이 false라면 else에 있는 실행문을 실행하는 것이다.
if (조건식){
실행문 1
}else if (조건식){
실행문 2
}else {
실행문 3
}
또 비슷한 형태의 if ~ else if ~ else 문이다.
만약 첫번째 조건식이 false라면 그 아래 else if의 조건식을 본다.
그 조건식이 true라면 실행문 2를 실행하고
만약 false라면 실행문 3을 실행한다.
else if는 계속 줄줄이 달아줄 수 있다.
bool a = true;
if (a){
Console.WriteLine("참이다.")
}else {
Console.WriteLine("거짓이다.")
}
조건식 안에 a가 들어가 있는데, 이 a는 true다.
때문에 '참이다.'가 출력되고 '거짓이다.' 는 출력되지 않는다.
int a = 12;
int b = 8;
if (a > 10 && b < 10){
Console.WriteLine("참이다.")
}else {
Console.WriteLine("거짓이다.")
}
두번째 예시문이다.
if문의 조건문을 보면 a는 10보다 크기 때문에 참이다.
그리고 b는 10보다 작기 때문에 참이다.
그리고 이 두 개의 식이 둘 다 참이므로
if문의 조건식은 참이된다.
고로 '참이다.'가 출력된다.
switch문
체감상 그렇게 자주 쓰는것 같지는 않지만
만약 조건식이 여러개 있을 경우, switch문을 쓰기도 한다.
형태는 아래와 같다.
switch(조건식)
{
case 조건:
실행문 1
break;
case 조건:
실행문 2
break;
case 조건:
실행문 3
break;
....
}
보시다시피 case는 얼마든지 붙을 수 있고
case가 끝날 때는 반드시 break를 넣어줘야 한다.
예시를 만들어보자
int num = 10;
switch(num / 10)
{
case 10:
case 9:
Console.WriteLine("잘했어")
break;
case 8:
Console.WriteLine("8점")
break;
case 7:
Console.WriteLine("7점")
break;
default:
Console.WriteLine("몰라")
break;
}
num은 10이고 num을 10으로 나누었을 때,
그 값이 10이거나 9면 "잘했어"를 출력하고
8이면 "8점", 7이면 "7점"을 출력하라는 알고리즘이다.
맨 위 case 10을 보면 아무것도 없고 바로 case 9로 넘어가는데
이는 만약 (num / 10)의 값이 10이거나 9이면 Console.WriteLine("잘했어")를 실행하라는 의미다.
맨 아래 default는 위의 조건들 중 어느것도 해당하는게 없을 경우
실행하는 부분이다.
반복문
반복문에는 for문, while문, do~while문이 있으며 기본적인 형태는 아래와 같다.